


配体化合物筛选服务



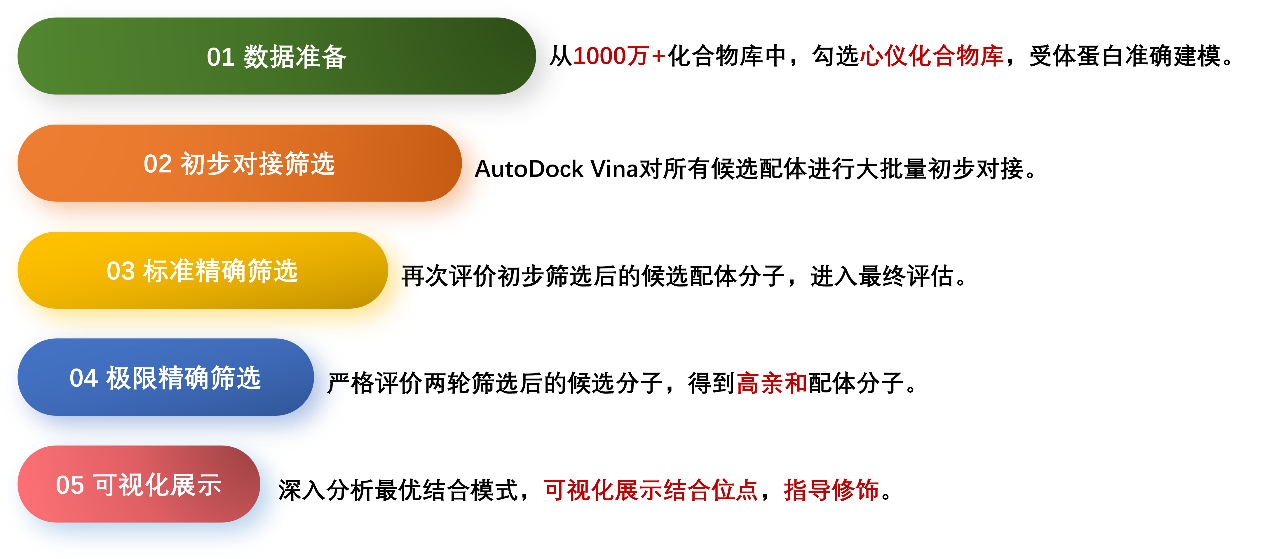
1 产品概述
本产品具有很强的定向性和灵活性。基于已知的靶点蛋白结构信息进行分子对接模拟,从而筛选出与受体结构高度匹配的化合物。同时,虚拟筛选可以随时调整筛选标准和参数,以适应不同的筛选需求,具有极高的灵活性和适应性。本产品不仅可以获得潜在的高亲和化合物,还可以通过分子对接和建模分析,提供化合物与靶点结合模式的信息。这种数据的可分析性和预测性能够帮助研究人员在筛选出潜在化合物后,进一步理解其结构-活性关系(SAR),为后续的化合物优化和药效改进提供支持。
2 产品筛选流程
2.1 构建个性化合物库和受体蛋白模型
科晶生物已储备1000万+化合物数据,包括分子结构、理化性质及成药性参数等。科研工作者可根据研究方向勾选心仪的化合物库,在缩小的筛选范围内发现高质量、高性价比的化合物,减少初期研究成本。
在确认蛋白质的名称、物种和氨基酸序列后,收集蛋白质的相关信息。若靶点蛋白无冷冻电镜解析的完整三维结构,技术人员会根据靶点蛋白的序列使用AlphaFold 3进行精准建模,评估模型的置信度,确保结构的准确性和可靠性。

图1 科晶生物已储备化合物库大类

图2 科晶生物按照疾病化合物库分类
2.2 初步对接筛选
本产品选择AutoDock Vina进行分子对接。使用默认对接参数,对所有候选化合物分子进行大批量的初步筛选。将结合能从低到高排布,结合能最低的前5%化合物分子进入下一轮“精确筛选”环节。
2.3 精确对接筛选
调高对接参数,控制对接过程的彻底程度,再次对接评价上一轮前5%的化合物分子,重新获得结合能分值,选取结合能最低的前5%化合物分子进入下一轮“极限精确筛选”环节。
2.4 极限精确筛选
候选化合物进入最终评估阶段,在算力承受范围内,将对接参数调整至最高。将所有候选化合物的最新结合能分值,按照从低到高排布,科研工作者可作为参考,从中选取化合物进行后续实验验证。
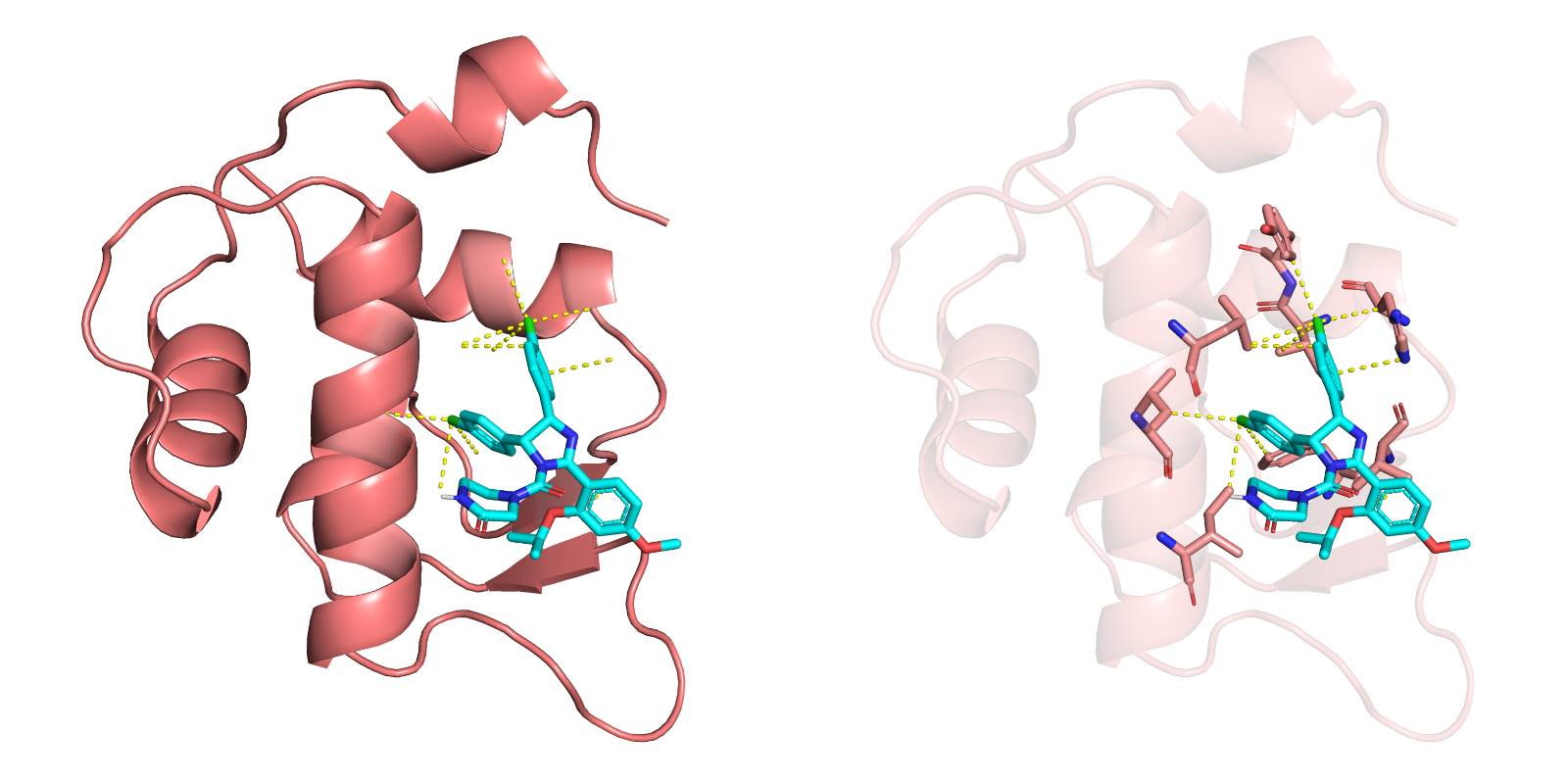
2.5 可视化展示结合构象(可选项目)
使用DiffDock、NeuralPlexer深入分析目标化合物-靶点蛋白的结合构象,按照置信度高低分析最佳结合模式,分析化合物基团与靶点蛋白氨基酸残基之间的连接,指导后续化合物修饰,提高活性和稳定性,减少药物毒性。
3 拟交付结果
1 | 个性化合物数字文库信息,包括化合物名称、CAS号、三维结构 |
2 | 靶点蛋白的三维结构模型,并提供建模评分 |
3 | 靶点蛋白与所有候选化合物的结合能原始数据 |
4 | 靶点蛋白与第一轮前5%候选化合物的结合能原始数据 |
5 | 靶点蛋白与第二轮前5%候选化合物的结合能原始数据 |
6 | 全数据Excel表格及项目服务报告 |
7 | (可选项目) 化合物与靶标蛋白的五种结合构象及对应的置信度得分, 并可视化展示最佳构象 |